How A little Market survived Capital
A few weeks ago, our PR announced us the good news. A little Market will be featured in Capital, in a documentary about professional reconversion. Great! Are we ready for this sudden traffic? Let’s start by clarifying what the so-called Capital effect is. Capital is a French TV show with in-depth documentaries on various subjects, most often linked to economics. Appearing in one of these documentaries usually leads to a sudden surge in your traffic pattern. It infamously brings your website down to the point that a twitter account is dedicated to the phenomenon, i.e. Slashdot effect. Of course, you usually know your company will appear only a few weeks before and this is an extra project that was not originally planned in the product or tech roadmap as is. So here are a few pointers on how A little Market prepared and survived the event.
First of all, this is not your typical IT project and clearly, you need to reach the good enough quality of service with an existing technical stack, which primary design is not to handle such a sudden surge of traffic increase. So, this situation begs for humbleness and is not a matter of a single person. After a first reflection about what very probably needed to be done, I identified some key owners:
- Alexandrine Boissière for every related to front-end caching: assets, static pages as well as user-behavior mimicking load testing.
- Vincent Paulin for the search engine caching and capacity planning, as well as the low hanging fruits for our database, which obviously was the bottleneck and weakest point of our infrastructure. He later on proposed a crawling tool to simulate load tests
- Thierry Gerbeau for the quality and verification of the overall process
- Olivier Garcia for a timeline of all actions to do before and after the broadcast, as well as the mobile apps and the background tasks to disable during the event
- Laurent Callarec for the capacity planning and the preparation with our partners: Morea and AWS as well as Varnish modifications and our User and shops API
- Sylvain Mauduit for the applicative features to disable and to figure out how to cache more contents for disconnected users.
- And myself for overall coordination.
Obviously, this would not have worked as a pure delegation process and we complemented this effort with a brainswarming activity involving the whole team in order to detect potential pitfalls. As far as project management is concerned, the rest was pretty standard agile process with a prioritized backlog and dedicated Daily Scrum
Let’s jump into the technical interesting gists of this adventure. Thanks to AWS, lots of components can easily scale-up horizontally. That being said, you still need to be careful. Indeed, we were expecting a flash traffic scenario. So we needed to ask AWS to pre-warm our load balancers. Also, each AWS account has some services limit, which can be changed. But you need to think about it beforehand. Finally, auto-scaling new instances is not instantaneous and might be too slow to accommodate a spike.
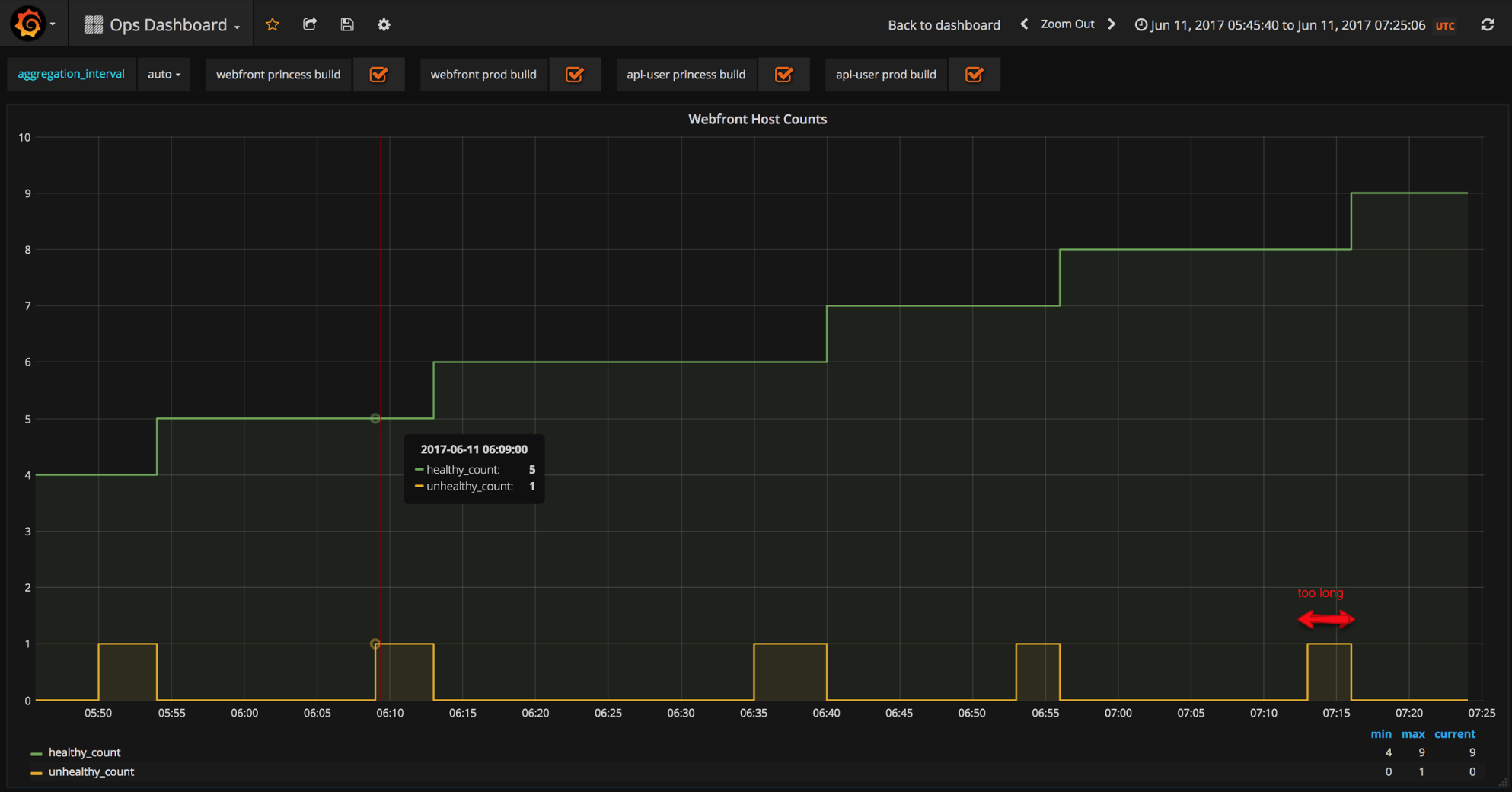 Normal autoscaling speed
Normal autoscaling speed
As a result, we decided to adapt our Auto Scaling groups and raise our minimum values.
This leads to the next aspect of this project: the capacity planning. Historical data gives us a little bit of hint on how our infrastructure scales with traffic. Unfortunately, since the expected traffic is an order of magnitude bigger, you cannot just do a regression (linear or not) to predict your needs. If you add to the equation that we plan to have a different website feature-wise (more on this later), then your historical data is just not enough and you need to simulate your load. So, in the days before the event, we ran quite a few load tests, using different technologies: selenium grid to play actual user interactions, in-house scraper in python to to crawl all the pages within our site - much like a bot would do - and siege based on filtered varnish access logs to reproduce real traffic. This allowed to fine tune our actions and approach the d-day with more confidence. Clearly, the bottleneck of our infrastructure was going to be the database, the rest scaling more or less with no real challenge through ELBs. One of the key element to survive was to handle the traffic of new users. Even though I would not recommend this for a long term solution, the easy quick win here was to rely on Varnish http caching for these users. So we added a cookie which presence allowed us to detect if a user was connected to his account or not, very easily at this level and have Varnish rules based on it. This allowed to warm-up and cache anonymous versions of the home page, shops and products. The second leverage point was to temporarily deactivate features which are heavy on the database. With the appropriate communication to the vendors, we decided to turn off all the seller’s back office where the stats and details of orders and other sub-optimal queries reside. Another system that was deactivated was the messaging system, because the anti-SPAM policy is also costly implemented for the DB. Since most of this is somewhat gut feeling and not easily demonstrable or verifiable beforehand that it will be enough, we also worked on fallback scenarios. The most drastic one was to develop a dedicated cacheable maintenance page, where a static form allowed us to collect email addresses through lambda function and storage in DynamoDB. The final precaution was to prepare in advance the timeline of events as well as a few PRs, ready to be merged and deployed, just in case.
Conclusion
We “only” had a 10x in traffic but the website handled it well. Here are few graphs and a video
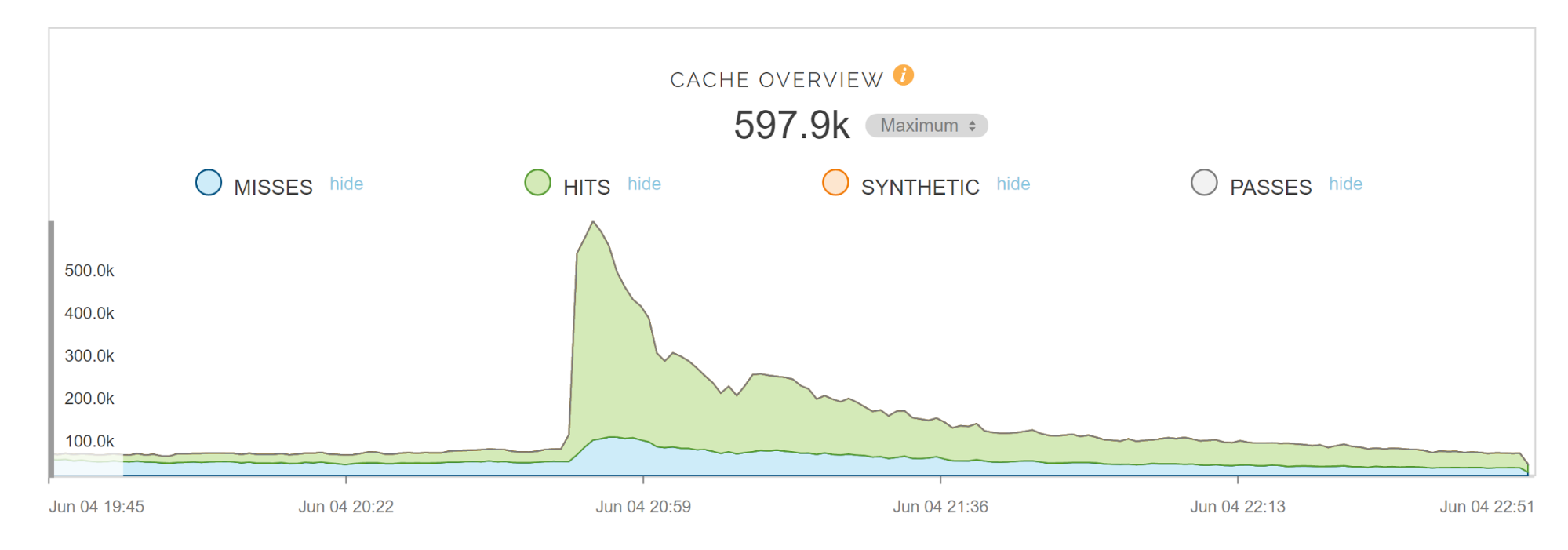 CDN
CDN
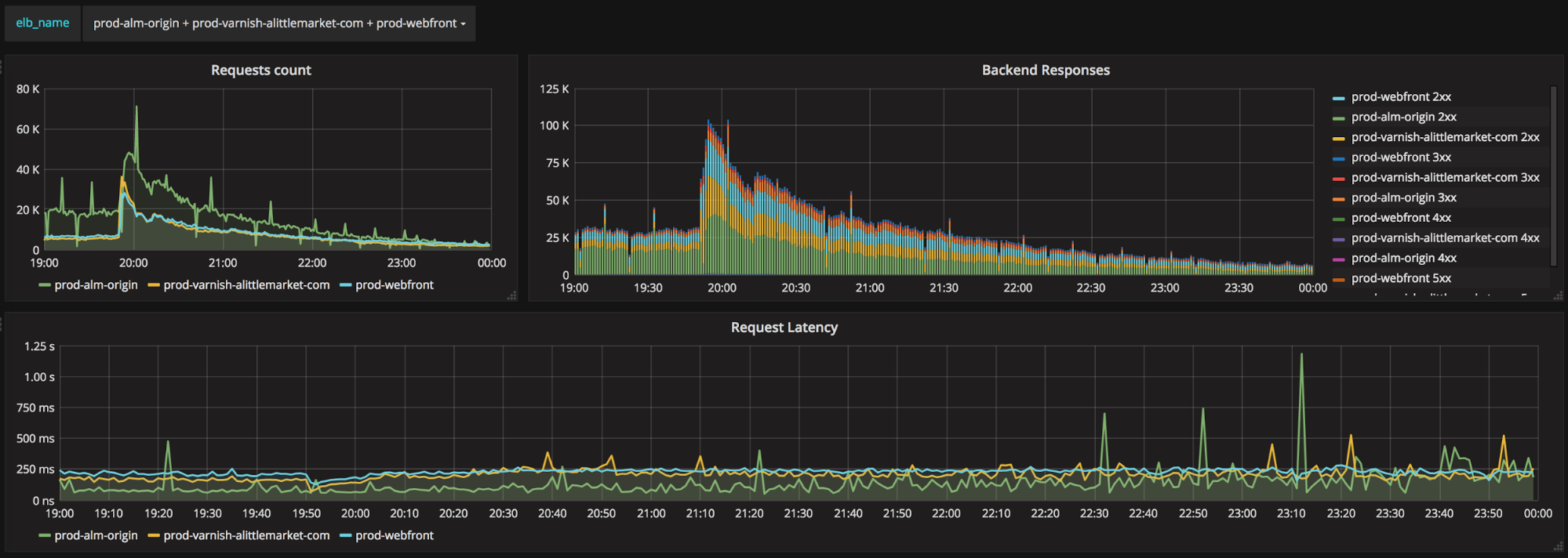 Requests count and latency
Requests count and latency
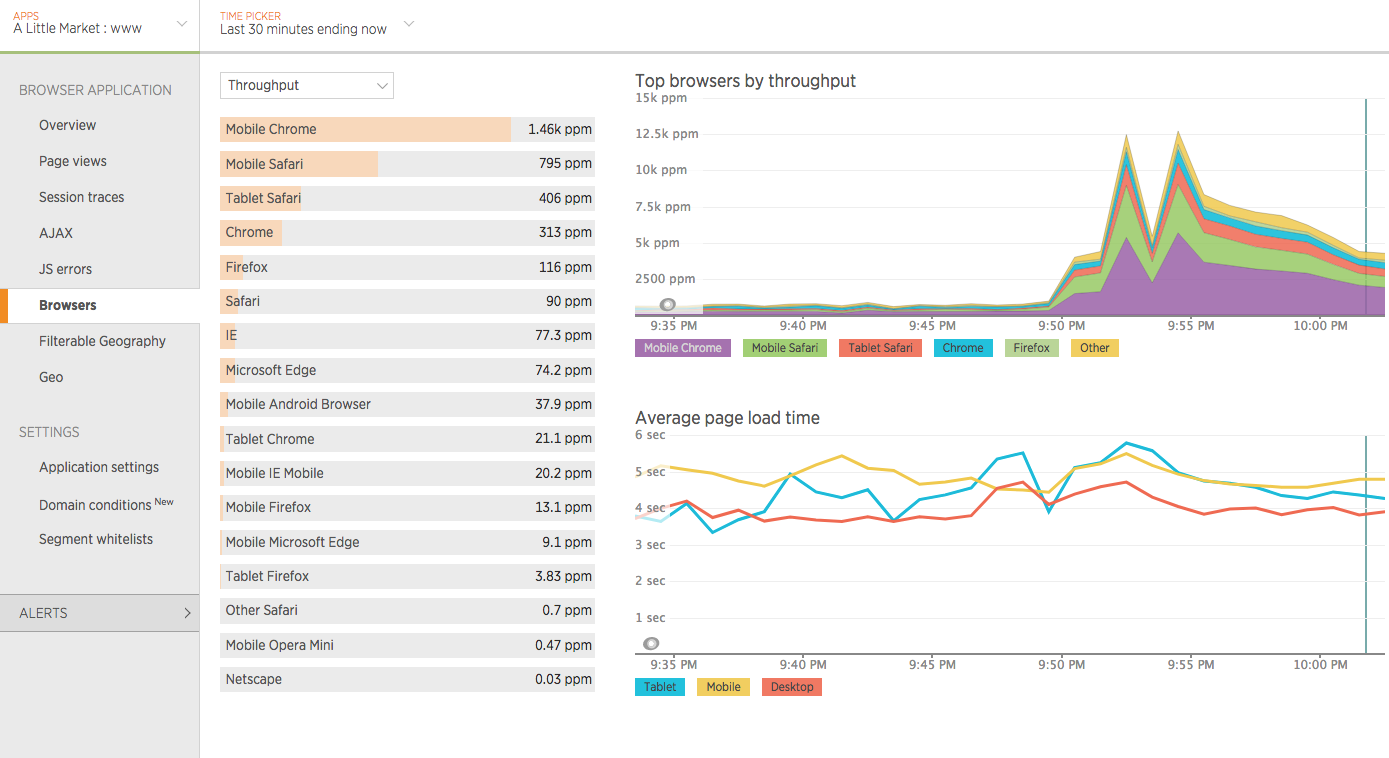 End-users throughput spike while maintaining average page load-time
End-users throughput spike while maintaining average page load-time
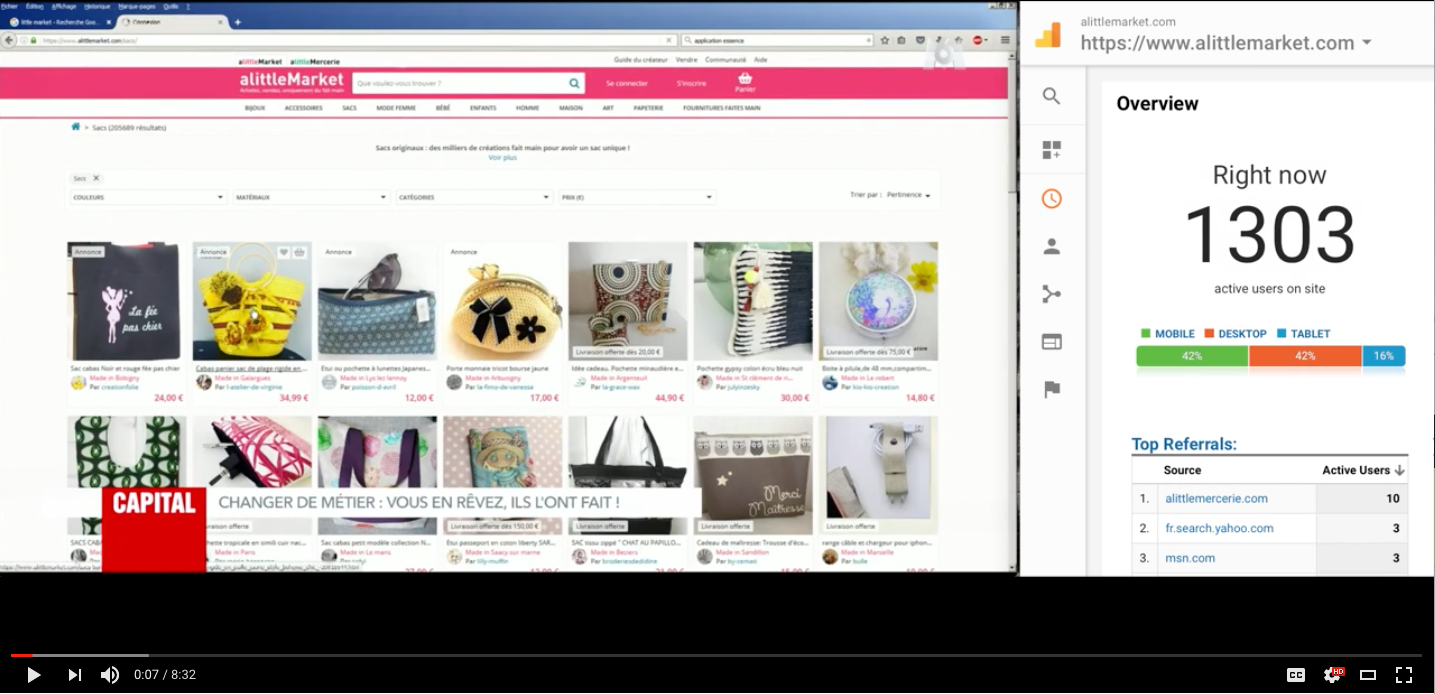 Follow the impact of the documentary on the number of live users using www.alittlemarket.com
Follow the impact of the documentary on the number of live users using www.alittlemarket.com