-
How A little Market survived Capital A few weeks ago, our PR announced us the good news. A little Market will be featured in Capital, in a documentary about professional reconversion. Great! Are we ready for this sudden traffic? Let’s start by clarifying what the so-called Capital effect is. Capital is a French TV show with in-depth documentaries on various subjects, most often linked to economics. Appearing in one of these documentaries usually leads to a sudden surge in your traffic pattern. It infamously brings your website down to the point that a twitter account is dedicated to the phenomenon, i.e. Slashdot effect. Of course, you usually know your company will appear only a few weeks before and this is an extra project that was not originally planned in the product or tech roadmap as is. So here are a few pointers on how A little Market prepared and survived the event.
First of all, this is not your typical IT project and clearly, you need to reach the good enough quality of service with an existing technical stack, which primary design is not to handle such a sudden surge of traffic increase. So, this situation begs for humbleness and is not a matter of a single person. After a first reflection about what very probably needed to be done, I identified some key owners:
- Alexandrine Boissière for every related to front-end caching: assets, static pages as well as user-behavior mimicking load testing.
- Vincent Paulin for the search engine caching and capacity planning, as well as the low hanging fruits for our database, which obviously was the bottleneck and weakest point of our infrastructure. He later on proposed a crawling tool to simulate load tests
- Thierry Gerbeau for the quality and verification of the overall process
- Olivier Garcia for a timeline of all actions to do before and after the broadcast, as well as the mobile apps and the background tasks to disable during the event
- Laurent Callarec for the capacity planning and the preparation with our partners: Morea and AWS as well as Varnish modifications and our User and shops API
- Sylvain Mauduit for the applicative features to disable and to figure out how to cache more contents for disconnected users.
- And myself for overall coordination.
Obviously, this would not have worked as a pure delegation process and we complemented this effort with a brainswarming activity involving the whole team in order to detect potential pitfalls. As far as project management is concerned, the rest was pretty standard agile process with a prioritized backlog and dedicated Daily Scrum
Let’s jump into the technical interesting gists of this adventure. Thanks to AWS, lots of components can easily scale-up horizontally. That being said, you still need to be careful. Indeed, we were expecting a flash traffic scenario. So we needed to ask AWS to pre-warm our load balancers. Also, each AWS account has some services limit, which can be changed. But you need to think about it beforehand. Finally, auto-scaling new instances is not instantaneous and might be too slow to accommodate a spike.
 Normal autoscaling speed
Normal autoscaling speedAs a result, we decided to adapt our Auto Scaling groups and raise our minimum values.
This leads to the next aspect of this project: the capacity planning. Historical data gives us a little bit of hint on how our infrastructure scales with traffic. Unfortunately, since the expected traffic is an order of magnitude bigger, you cannot just do a regression (linear or not) to predict your needs. If you add to the equation that we plan to have a different website feature-wise (more on this later), then your historical data is just not enough and you need to simulate your load. So, in the days before the event, we ran quite a few load tests, using different technologies: selenium grid to play actual user interactions, in-house scraper in python to to crawl all the pages within our site - much like a bot would do - and siege based on filtered varnish access logs to reproduce real traffic. This allowed to fine tune our actions and approach the d-day with more confidence. Clearly, the bottleneck of our infrastructure was going to be the database, the rest scaling more or less with no real challenge through ELBs. One of the key element to survive was to handle the traffic of new users. Even though I would not recommend this for a long term solution, the easy quick win here was to rely on Varnish http caching for these users. So we added a cookie which presence allowed us to detect if a user was connected to his account or not, very easily at this level and have Varnish rules based on it. This allowed to warm-up and cache anonymous versions of the home page, shops and products. The second leverage point was to temporarily deactivate features which are heavy on the database. With the appropriate communication to the vendors, we decided to turn off all the seller’s back office where the stats and details of orders and other sub-optimal queries reside. Another system that was deactivated was the messaging system, because the anti-SPAM policy is also costly implemented for the DB. Since most of this is somewhat gut feeling and not easily demonstrable or verifiable beforehand that it will be enough, we also worked on fallback scenarios. The most drastic one was to develop a dedicated cacheable maintenance page, where a static form allowed us to collect email addresses through lambda function and storage in DynamoDB. The final precaution was to prepare in advance the timeline of events as well as a few PRs, ready to be merged and deployed, just in case.
Conclusion
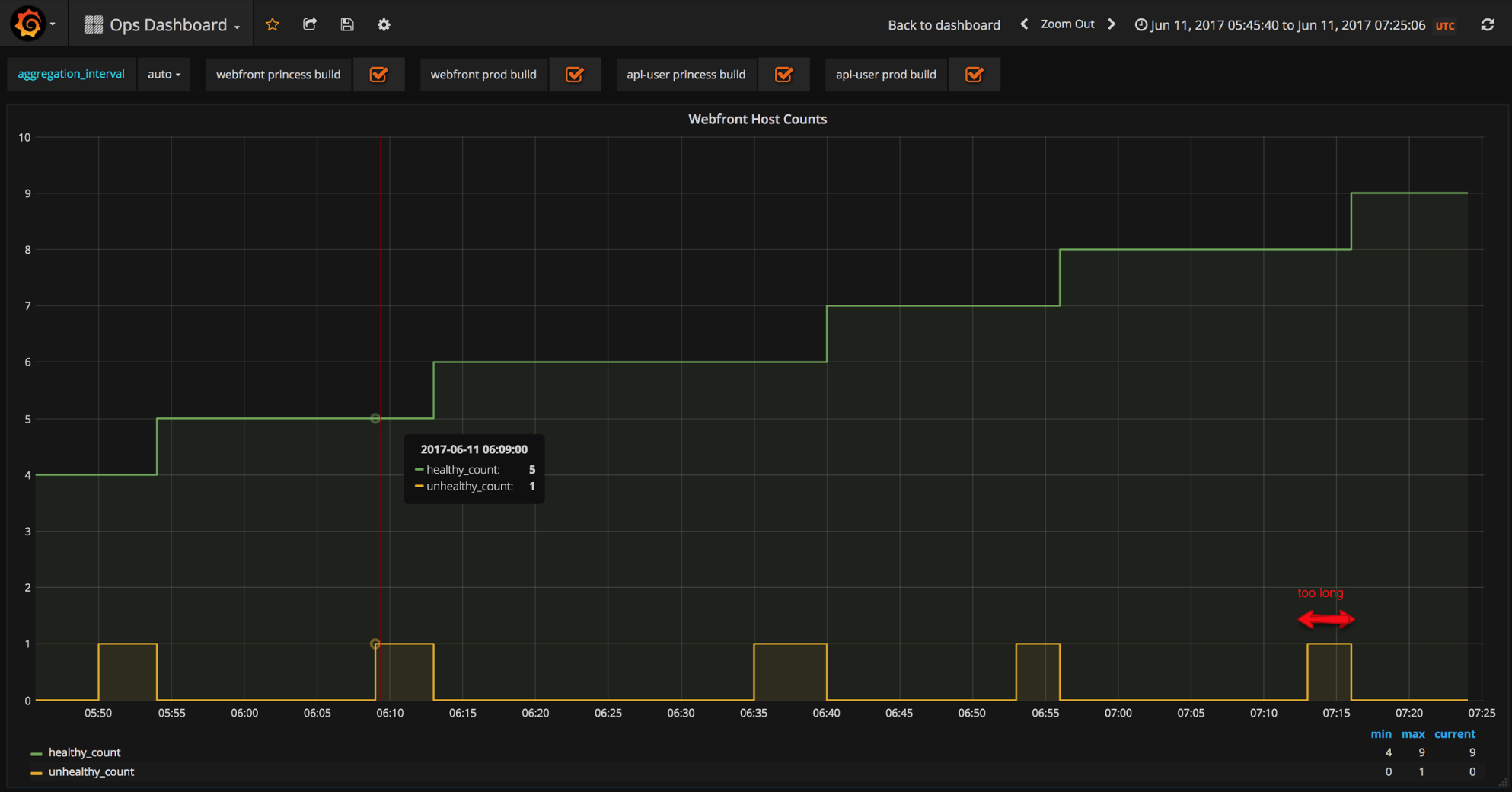
We “only” had a 10x in traffic but the website handled it well. Here are few graphs and a video
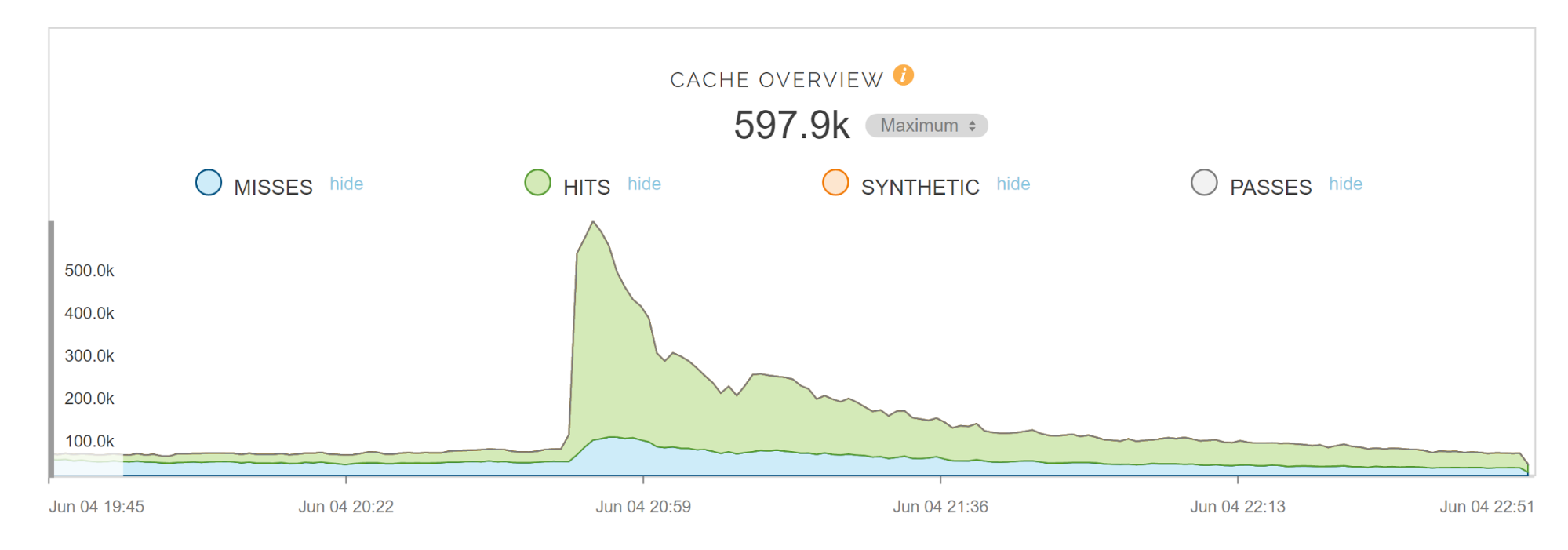 CDN
CDN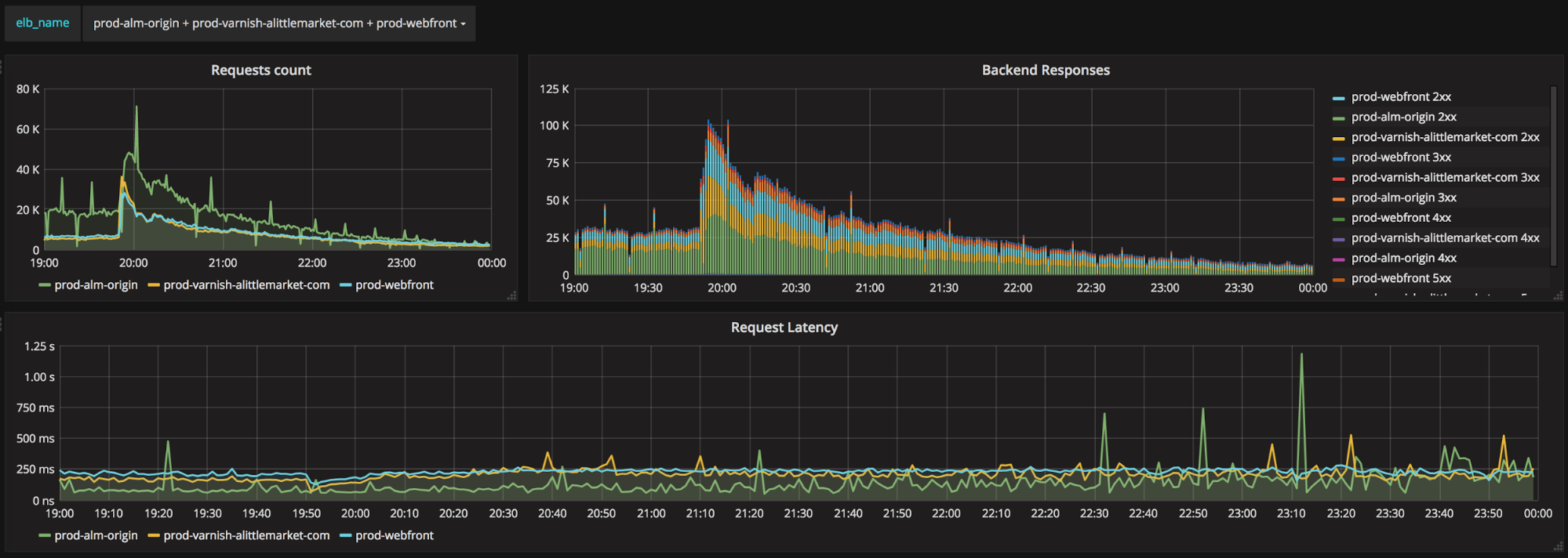 Requests count and latency
Requests count and latency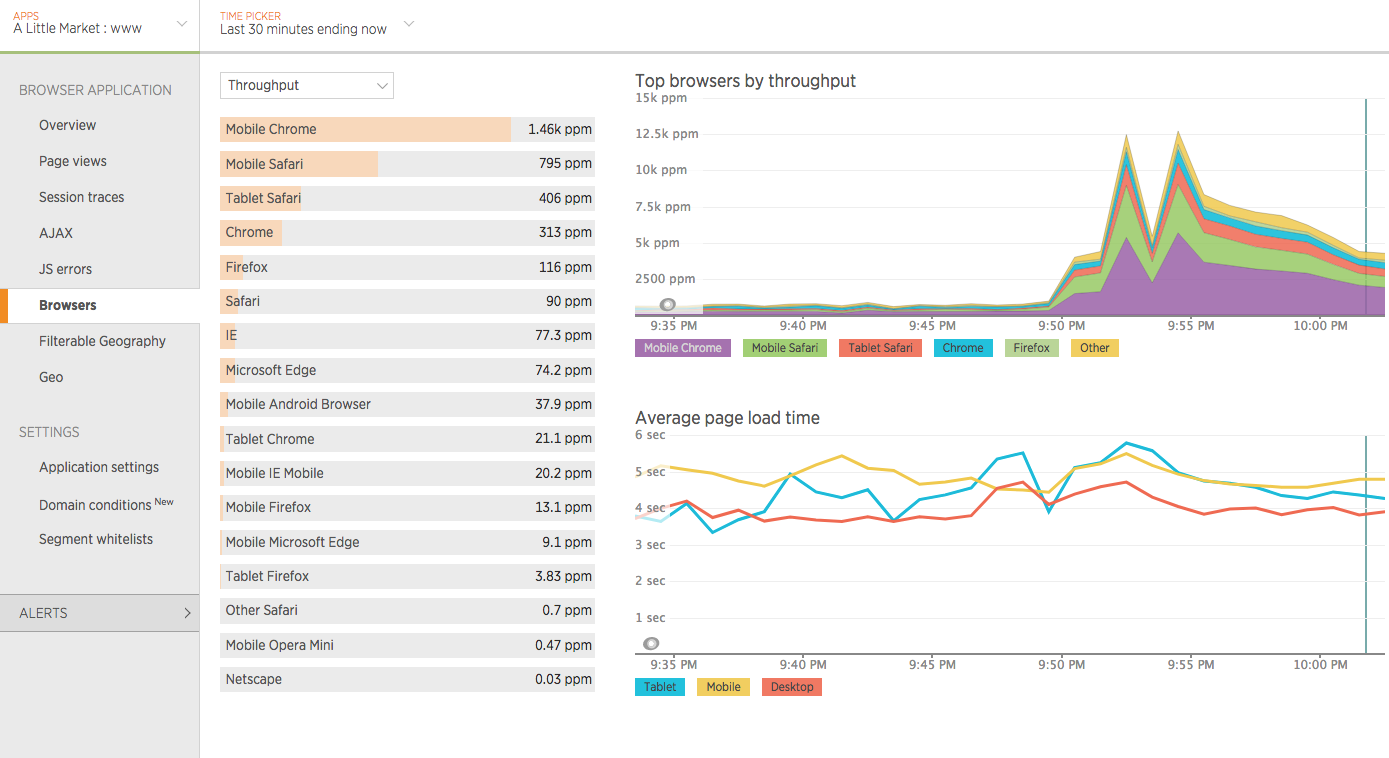 End-users throughput spike while maintaining average page load-time
End-users throughput spike while maintaining average page load-time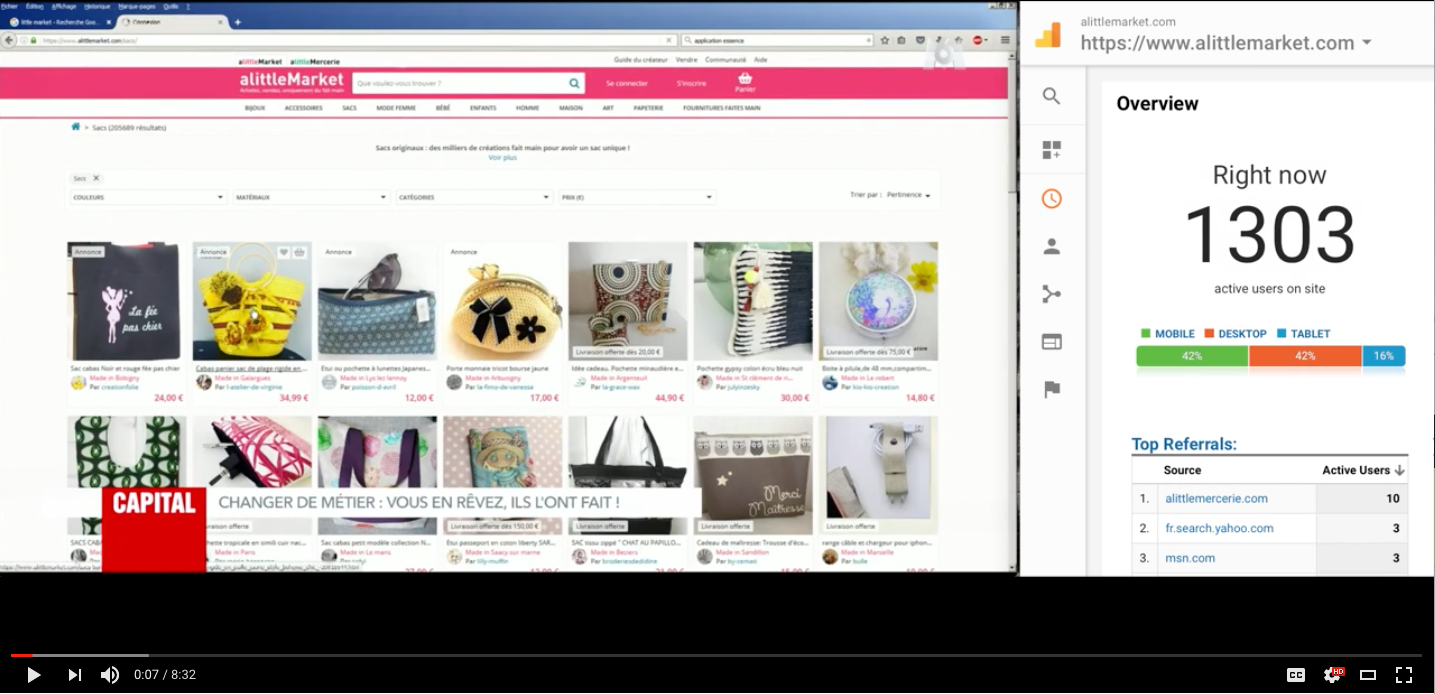 Follow the impact of the documentary on the number of live users using www.alittlemarket.com
Follow the impact of the documentary on the number of live users using www.alittlemarket.com -
Responsive webdesign & Mobile First Workshop This workshop took place during march 2015 and intended to raise awareness among employees in the Etsy France / A little Market teams.
-
How a HackWeek project got to be featured in App Store Best of 2016 It’s July 25th 2016, day one of the Etsy France Hack Week. For the second year in a row, we’ve made sure we’ve left room for innovation.
A HackWeek is a time during when employees get to do something different from their day-to-day responsibilities and innovate. This year we’ve had an algorithm that ranked images based on their quality, an internal user management system, and many more.
Another was a tvOS app for A little Market. Here we’ll take you through how it went from a Hack Week project becoming featured in Apple’s App Store Best of 2016.


tvOS
I had been reading up on tvOS for a while but had never really had a reason to go any further. With the HackWeek coming up, I thought that working on a tvOS version of A little Market would be an interesting direction to go, both for the business and for me as a developer. I had no idea how challenging that was going to be.
New User Interface Challenges
First things first, what was the app going look like? As you no doubt know, Human Interface Guidelines are very different when moving from one platform to another.

Apple TV does not have a mouse that allows users to directly select and interact with an app, nor are users able to use gestures and touch to interact with an app. Instead, they use the new Siri Remote or a game controller to move around the screen.
In addition to the new controls, the overall user experience is drastically different. Macs and iOS devices are generally a single-person experience. A user may interact with others through your app, but that user is still the only person using the device. With the new Apple TV, the user experience becomes much more social. Several people can be sitting on the couch and interacting with your app and each other. Designing apps to take advantage of these changes is crucial to designing a great app. Given that, we had to go back to the root of our product. Which means figuring out what the user core experience is / was, and making sure it was our focus.
Code
tvOS is derived from iOS but is a distinct OS, including some frameworks that are supported only on tvOS. You can create new apps or use your iOS code as a starting point for a tvOS app. Either way, you use tools (Xcode) and languages (Objective-C, Swift, and JavaScript) that you are already familiar with.
There’s one thing that needs to be addressed: TVML. For those who don’t know what it is, it’s a set of tools and frameworks using JavaScript and XML templates used to create tvOS apps easily. We’ve decided not to go with it, simply because we wanted the app to be 100% written in Swift. Code such as WebServices, models and a few others are being shared with the iOS app.
App Store
We had managed to get a hold of a contact at the App Store, who helped us implementing the guidelines. This involved some going back and forth between TestFlight builds and their feedback. It was amazingly constructive and without doubt helped us raise our app quality. A week after the HackWeek, we decided to ship the tvOS app. A couple days after the validation, we got an email saying that the app was going to be featured on launch! It was an amazing result and the team here were incredibly excited. It was a first for us, and the marketing guidelines were understandably strict but we managed to get by. Fast forward a few months and our app had been chosen in the App Store Best of 2016 too, which was beyond all expectations.

Shortly after, some of the magic rubbed off on iOS too, as the ALM app was featured in Apps of the Week too…
Conclusion
While the number of apps is low (relative to iPad and iPhone/iPod touch), I’ve found the average quality of tvOS to be much higher. Most Apple TV apps are made by more established developers who already have an iOS version of the app.
My advice to you: Go for tough challenges, anticipate and implement new Apple features as they get released, and have fun developing!
Thanks for reading!
-
How Etsy France migrated all its sites to HTTPS When Etsy acquired A little Market, the migration of our sites to https which was on the shelf since a few years became one of our top priority projects in mid 2015.
But before starting such a big and impacting project, we went through a long preparation phase.Project preparation
Why
As A little Market is growing up day after day, it was becoming increasingly important to securise our applications to prevent session hijacking, data sniffed, etc.
Our users are also more and more aware about security, especially when money is involved. It is our mission to reassure them on the reliability of the applications they use every day.
All sites worthy of the name must be accessible through HTTPS for all these reasons and also for their image.That’s why we decided that HTTPS migration was a priority in mid 2015.
Goal
The goal of this project was to force all our users to access our services through HTTPS connections. Google and other search engines would have to crawl our websites only in HTTPS to avoid duplicate content.
Main impacted services:
- alittleMarket.com
- alittleMarket.it
- alittleMercerie.com
- Internal Api
How
We want to switch smoothly and easily from HTTP to HTTPS. At most, we want to update a few configuration values to do it progressively. All the blocking points to use HTTPS will have to be fixed before the deadline.
Acceptance criteria
All our applications must be accessible through HTTPS.
All users accessing the websites through HTTP must be redirected to HTTPS using 301 (301 redirections are very important for Search engines).When to switch ?
A switch from HTTP to HTTPS can have a big impact on search engine’s ranking. As we do not use paid marketing, a bad indexing in search engines and especially Google can have really bad consequences on our traffic. Thanks to previous experiences, our SEO consultant estimated that SEO traffic returns back to normal around 3 months after switching.
Because we had several marketing operations during the year (winter and summer sales, private sales, Christmas, etc.) and we didn’t want a big impact on our SEO traffic during these operations, we carefully determined the periods when the switch could be made. We only found two:- February at the end of the winter sales (traffic should return back to normal around May)
- July at the end of the summer sales (traffic should return back to normal around October)
Milestones
- Dependencies
- List all the dependencies of our main applications (ex: assets, blogs, images, etc)
- These dependencies will have to be migrated first.
- Incompatible subdomains
We know some of our hostnames contain more than one subdomain level (ex: static.commun.alittlemarket.com) but we don’t want to buy expensive certificates that cover every level.- List all the concerned hostnames
- Fix incompatible subdomains (ex: static.commun.alittlemarket.com -> static-commun.alittlemarket.com). Fix them means:
- Create new subdomains in apache
- Add them in Route53
- Update our stack to use them instead of the previous ones
-
Monitoring
Monitor HTTP and HTTPS traffic using Statsd - Hardcoded URLs
Many links to our applications within our codebase are hardcoded- Determine each type of hardcoded URL (ex: http://www.alittlemarket.com, http://CONSTANT, http://assets.alittlemarket.com, etc)
- Replace all the hardcoded URLs by the equivalent constant
- Project by project
- file type by file type (php, smarty, twig, translations, etc.)
- URL type by URL type
http://alittlemarket.com, http://www.alittlemarket.com, http://CONSTANT, http://www.OTHER_CONSTANT, http://assets.alittlemarket.com, etc. - URLs in database (sites and blogs)
- Google tools
- Google Search Console
Create new entries for HTTPS sites - Google Analytics
Differentiate HTTP traffic from HTTPS traffic: we used Google Analytics’ fifth custom var to store the scheme
_gaq.push(['_setCustomVar', 5, 'Scheme', window.location.protocol.replace(/:$/, ''), 3]);
- Google Search Console
- Force HTTPS
Requests going through HTTP must be redirected to HTTPS
We don’t want to block HTTP traffic
Execution
We were two then three to work on this project during 4 months, between November 2015 and February 2016.
It was a hard task as you can imagine due to the innumerable amount of hardcoded URLs everywhere in the codebase, the many dependencies that also needed to migrate to HTTPS, and the risk of losing SEO traffic.We took the opportunity to standardize contants usage and to send an alert when a new hardcoded URL is committed (we don’t want to repeat that experience).
- Renamed subdomains (including prod and princess environments): 16
- Migrated dependencies: 17
- Hardcoded URLs removed: more than 1,700
During the project development, we never blocked the access to our sites through HTTPS but this protocol had a specific robots.txt file to prevent search engines from crawling.
This played tricks on us on D-day…# HTTPS robots.txt User-agent: * Disallow: /But one important thing not to do is to disallow HTTP traffic from search engines once the switch is done.
If you do, search engines can’t calculate the new position of the HTTPS pages. You must allow HTTP traffic and redirect it using a 301 to the HTTPS version.We also used a HSTS header for all incoming requests to warn web browsers that they should only interact with our applications using HTTPS scheme.
# Virtual hosts SetEnvIf X-Forwarded-Proto https REQUEST_IS_HTTPS Header always set Strict-Transport-Security "max-age=31536000" env=REQUEST_IS_HTTPSGradual activation
One of our goal was to progressively enable HTTPS on our applications, we didn’t want to enable it for everybody at once.
But on our websites, some of the oldest pages use the html tag<base href="http://www.alittlemarket.com/" />that we didn’t succeed in removing without breaking many links everywhere. The link in this tag is managed by a configuration file and could not change based on the user accessing the page.We decided to hack this feature to be able to adapt this link depending on the visited URL. In other words, if a user visits the website in HTTP, the link has to be http://www.alittlemarket.com; and if a user consults the website in HTTPS, the link has to be https://www.alittlemarket.com. So, a user arriving in HTTPS on one of our websites stays in HTTPS during his entire session.
It looks like:
<?php if (array_key_exists('HTTP_X_FORWARDED_PROTO', $_SERVER)) { $scheme = $_SERVER['HTTP_X_FORWARDED_PROTO']; } else { $scheme = DEFAULT_HTTP_SCHEME; } if (!defined('HTTP_PATH_APP_DOMAIN_NAME')) { define('HTTP_PATH_APP_DOMAIN_NAME', sprintf('%s://%s', $scheme, HTTP_APP_DOMAIN_NAME)); }Activation on our preprod environment “Princess”
The first step was to enable HTTPS on our Princess environment :
- Princess configuration was updated: constant
DEFAULT_HTTP_SCHEMEwas changed to https -
Princess virtual hosts were also updated to accept HTTP and HTTPS (we used Apache module mod_macro to avoid repeating ourselves in each vhosts)
# force_ssl.conf <Macro ForceSsl> RewriteCond %{HTTP:X-FORWARDED-PROTO} ^http$ [NC] RewriteRule (.*) https://%{HTTP_HOST}%{REQUEST_URI} [L,R=301] </Macro># hsts_header.conf <Macro HstsHeader $max_age> SetEnvIf X-Forwarded-Proto https REQUEST_IS_HTTPS Header always set Strict-Transport-Security "max-age=$max_age" env=REQUEST_IS_HTTPS </Macro># We only added those lines in each princess vhost Use ForceSsl Use HstsHeader 3600
Prod environment remained unchanged.
Everybody who wants to deploy a feature in production (several times a day) must test it first on Princess. So, everybody was testing HTTPS on Princess without thinking about it during several days.
Our team (Core team) and our QA team had also tested HTTPS during all the process.
Activation on production (for admin only)
After one week of tests on Princess, we decided to enable the feature on production but just for the admins.
So, when someone was detected as being an admin and was surfing on HTTP, he was automatically redirected to HTTPS by the application layer.We used a listener which was plugged on the Symfony onKernelRequest event.
It looked like:<?php // SecuredRequestSchemeListener.php class SecuredRequestSchemeListener implements EventSubscriberInterface { /** @var SecurityContextInterface */ private $context; /** @var string */ private $env; /** * @param SecurityContextInterface $context * @param string $env */ public function __construct(SecurityContextInterface $context, $env = null) { $this->context = $context; $this->env = $env; } /** * @param GetResponseEvent $event * @return RedirectResponse|null */ public function onKernelRequest(GetResponseEvent $event) { $request = $event->getRequest(); if ($this->context->isGranted('ROLE_ADMIN') && false === $request->isSecure()) { $event->setResponse(new RedirectResponse($this->forgeHttpsResponseUrl($request))); } } /** * {@inheritdoc} */ public static function getSubscribedEvents() { return [ KernelEvents::REQUEST => ['onKernelRequest', KernelRequestListenerPriorities::FIREWALL], ]; } /** * @param Request $request * @return string */ private function forgeHttpsResponseUrl(Request $request) { return sprintf('https://%s', $request->getHost() . $request->getRequestUri()); } }And the service definition was:
<service id="alittle.security.secured_request_scheme_listener" class="ALittle\EventListener\SecuredRequestSchemeListener"> <argument type="service" id="security.context"/> <argument>%kernel.environment%</argument> <tag name="kernel.event_subscriber" /> </service>Thanks to the “trick” used to define
HTTP_PATH_APP_DOMAIN_NAMEconstant, after a first redirection from HTTP to HTTPS, admins stayed in HTTPS during their entire session, even on the oldest pages.Activation for everybody application by application
The big day was February 29th.
The plan was to:- Create a war room contaning one person of each service (customer service, communication, technical teams, QA, SEO members, etc.)
- Switch the applications one by one (alittleMarket.it, alittleMarket.com, alittleMercerie.com)
- Open traffic through HTTPS
-
301 redirections for incoming traffic though HTTP
RewriteCond %{HTTP:X-FORWARDED-PROTO} ^http$ [NC] RewriteRule (.*) https://%{HTTP_HOST}%{REQUEST_URI} [L,R=301] - Update all the sitemaps (a cronjob to relaunch) to use HTTPS URLs instead of HTTP
- After each switch, everybody in the war room had to check that everything was working correctly (metrics, functional tests, social networks, forums, etc.)
- Drink some beers after that big day !
D-day traffic metrics
As you can see on the metrics below, we monitor global HTTP and HTTPS traffic, the traffic for each website, and Google bot traffic.
On the 3 graphs (ALM IT, ALM FR, and ALME FR) we saw that the HTTP traffic abruptly stops and at the same moment the HTTPS traffic starts. That’s when we switched.
On the global traffic we saw the same impact at the same times.Finally, we saw a strange thing on the Google bot traffic. At 2pm (14:00) we see that Google bot http traffic stops but the HTTPS traffic does not start. It’s not normal and we were worried about that. We couldn’t afford to lose SEO. After some research, we discovered that Google had cached the robots.txt file we served it when it came through HTTPS (it was a different file than the HTTPS robots.txt file). In that file, to avoid duplicated content, we disallowed everything which is why it stopped crawling them.
Fortunately, we discovered that problem very quickly and 1.5 hours later, Google crawled our applications again. We only needed to send the good robots.txt in Google Search Console.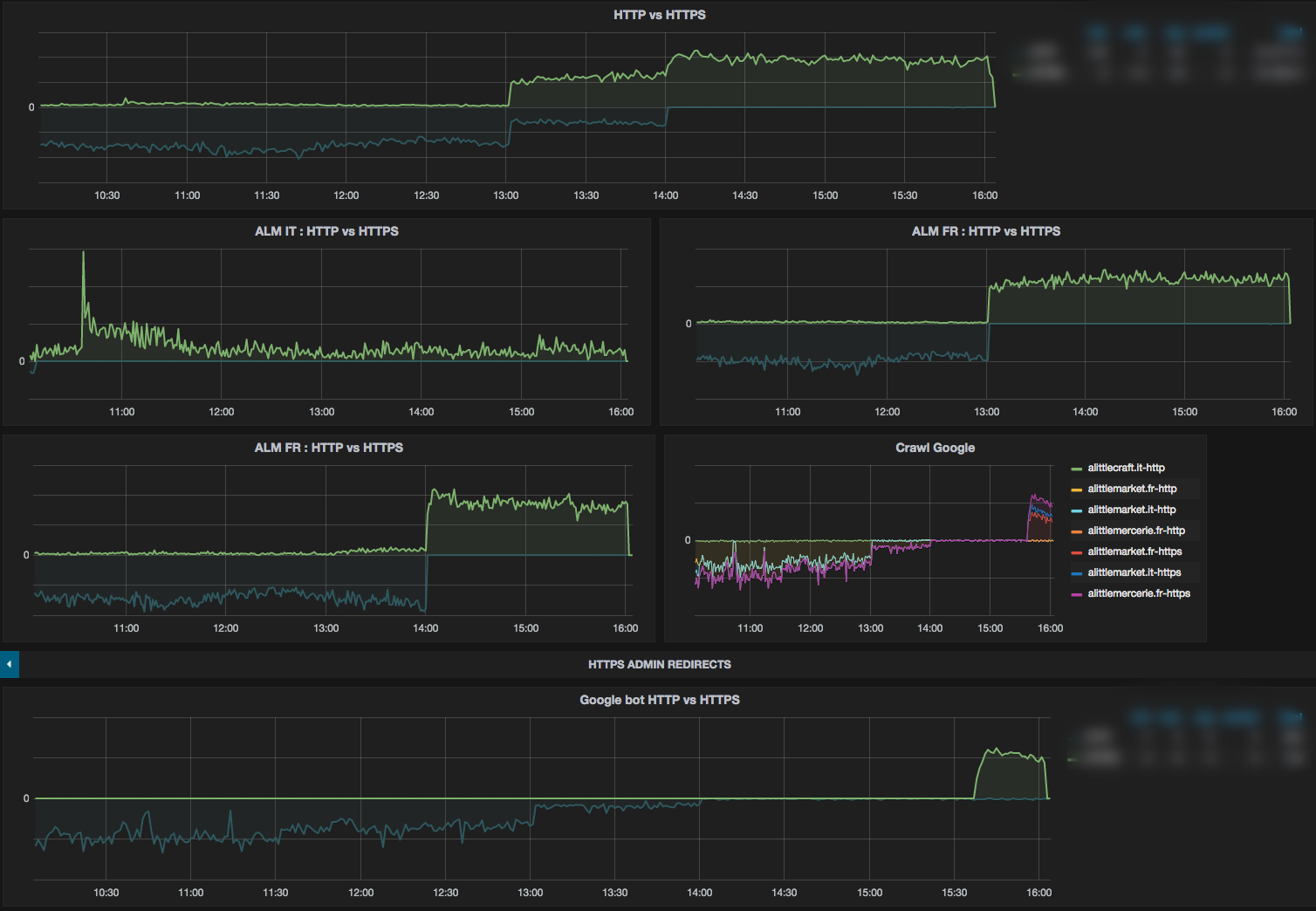
Bugs
We found only one bug due to the switch.
The bug was due to an external javascript library (used for the Mondial Relay delivery service) that we still called using HTTP.
Web browsers did not load the external javascript and the customers who chose Mondial Relay as delivery mode couldn’t choose the relay point where they wanted to be delivered…
To fix the bug we couldn’t simply change the URL to use HTTPS because the library wasn’t available through that protocol. We had to upgrade the version of the library. Fortunately, it only involved small changes and the bug was fixed quickly.What happened next?
Google indexation
Thanks to 301 redirection from HTTP to HTTPS on every page of the sites, Google started to crawl pages using HTTPS as soon as we switched the scheme. No more pages were crawled using the HTTP scheme.
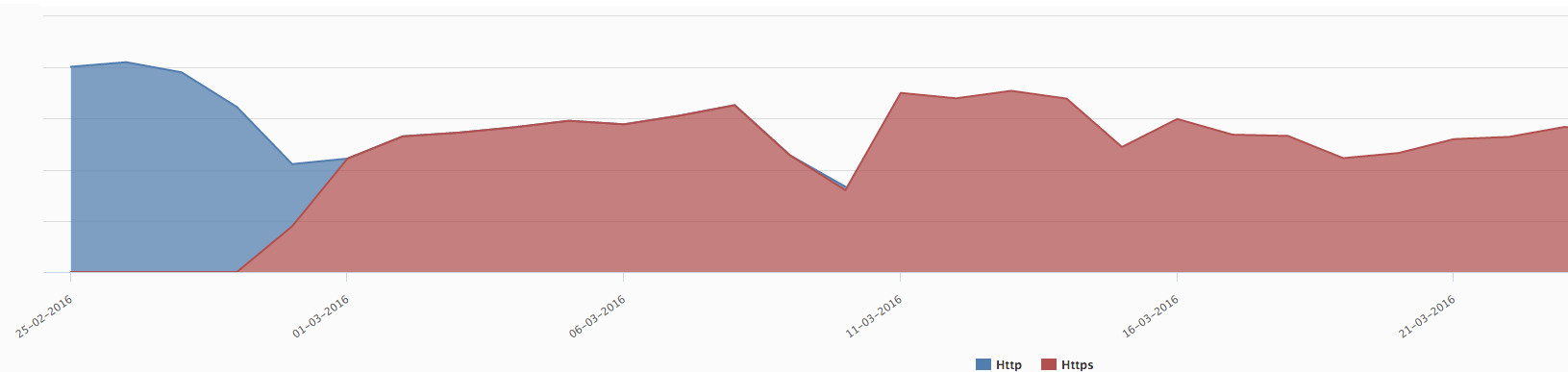 HTTP and HTTPS crawl over time (February to March 2016)
HTTP and HTTPS crawl over time (February to March 2016)However, that doesn’t mean that Google had replaced all the URLs in its index by the HTTPS version. It simply means that it continued to crawl using HTTP and was redirected to HTTPS.
We noticed the HTTPS version of the main pages appeared in Google results one day after the switch.Then, around 80% of the indexed pages had been replaced after 1 month.
The deeper pages had been replaced in the Google index after about 3 months.
 HTTP Response code in march 2016
HTTP Response code in march 2016 HTTPS Response code in march 2016
HTTPS Response code in march 2016Quickly, Google stopped crawling our sites using HTTP in favor of HTTPS
Traffic disturbances
Three months after the switch, our traffic from Google recovered to its normal trend.
E-commerce sites migrating from HTTP to HTTPS can lose 40% of their traffic during several months. A little Market and A little Mercerie lost much less traffic and only for three months. As you can see on the graph below, the impact of the HTTPS migration on SEO traffic was not significant. According to Google Analytics SEO traffic slightly decreased
According to Google Analytics SEO traffic slightly decreasedEtsy France’s technical team successfully performed that big challenge thanks to several measures including SEO.
Thanks for reading!
-
Git Survival Kit workshop This workshop is about the basic commands to know to survive with Git
-
The technical workflow at Etsy France (Part 1) Here at Etsy France we’ve tried several management techniques such as everything and nothing. But for some time now, we’ve completely switched to a Scrum agile development methodology. In order to manage our workflow we interconnected some very useful tools such as Jira, GitHub, HipChat and Travis CI.
This post will explain you what our daily workflow looks like from the early backlog to the production deployment.Team or Teams ?
Last year, we decided to completely change our work habits.
We went from one big team (basically the entire company) to 6 smaller ones, each composed of up to 7 people with tech and non-tech backgrounds.
Why so many teams?
Well, simply because as our website grew, our tech team did and regular tech meetings with 10+ people are just boring.But more importantly, it allowed each of our departments to have their projects in their hands and the means to move forward by managing their own timeline.
Each team works on its own weekly backlog on JIRA. Most of them are following Scrum development methodology, while some are using Kanban.
In the Scrum method of Agile software development, work is confined to a regular, repeatable work cycle, known as a sprint or iteration.
Each task in those iteration is going through 5 different states represented by 5 columns:- To do
- (Waiting)
- In progress
- Should be reviewed/tested
- Done
This is how it works :
- To do: A task that will be done in the current sprint but yet to begin
- Waiting: More details are needed in order to begin/continue this task (optional step)
- In progress: Development is in progress
- Should be reviewed/tested: Development is finished but the task should be reviewed and tested by another developer or project member
- Done: Task deployed and tested in production
The tools
Git and GitHub are fully integrated to our workflow.
The GitHub integration in Jira is very useful and offers an overview of our past/current/future developments in a single spot.
To use this interaction between these tools, we use the DVCS plugin in Jira which allows you to link your GitHub account directly in Jira. You can select the repositories you wish to link or choose future repositories to auto-link.Then, a connection between Jira and GitHub is automatically created when:
- a message containing the name of the Jira task is being committed (e.g.: CORE-542)
- a branch having the same name as the Jira task is being created
- a Pull Request with a title containing the name of the Jira task is being created
By doing so, you are able to find all the commits, branches and pull requests linked to your Jira task:
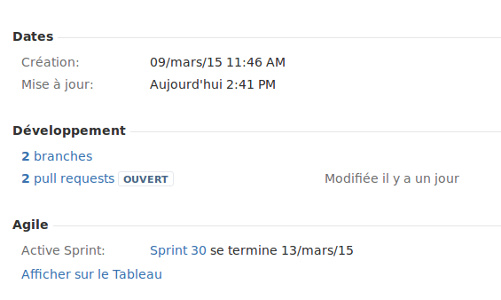
The connection between GitHub and Jira is definitely helpful to us.
Here are a couple things we can do with it:- We can easily access every pull request related to the current Jira ticket. No more wasting time looking around for pull requests on each repository, it can be really tedious at times.
- In case of bug (or what is considered as one) it’s easier to find the responsible code for the issue, go back to the pull request and then to find the Jira task containing all the functional specifications.
This trick is needed because we don’t have the culture of small and atomic commits with explicit comments yet.
Back to our workflow
When a task switches to “In progress”, a git branch with the same name as the Jira task is created.
Development begins.
When the task has been done, it goes to the column “Should be reviewed/tested” in Jira and a pull request is created in GitHub.
Then Travis comes around !
And since we linked it to GitHub, each Push or Pull Request being created sends a build request. By doing so, we can quickly see if the development branch doesn’t pass some tests and automatically alerts us. All that without leaving GitHub.
Very useful.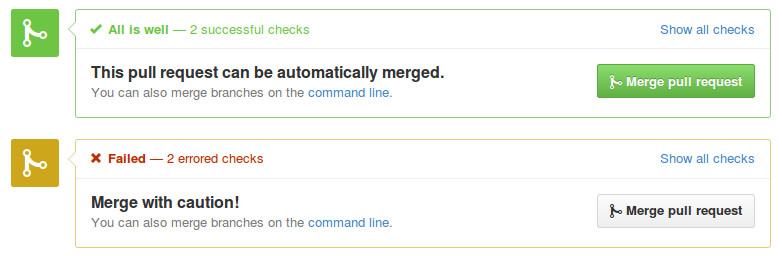
As in Jira with the columns, we use labels in GitHub to reflect the PR status:
- WIP (Work In Progress) in red
- RFR (Ready For Review) in yellow
- RFM (Ready For Merge) in green
HipChat warns the others members of the team that the task is ready for review.

At this time, the pull request should be reviewed by at least one other engineer before being merged into master.
Each pull request must have one in order to be merged.
in order to be merged.You did it !
When the pull request has been validated, it can safely be merged and deployed to a pre-production environment for a last safety check, and then to production.
This is another step in our workflow.To be continued…
subscribe via RSS